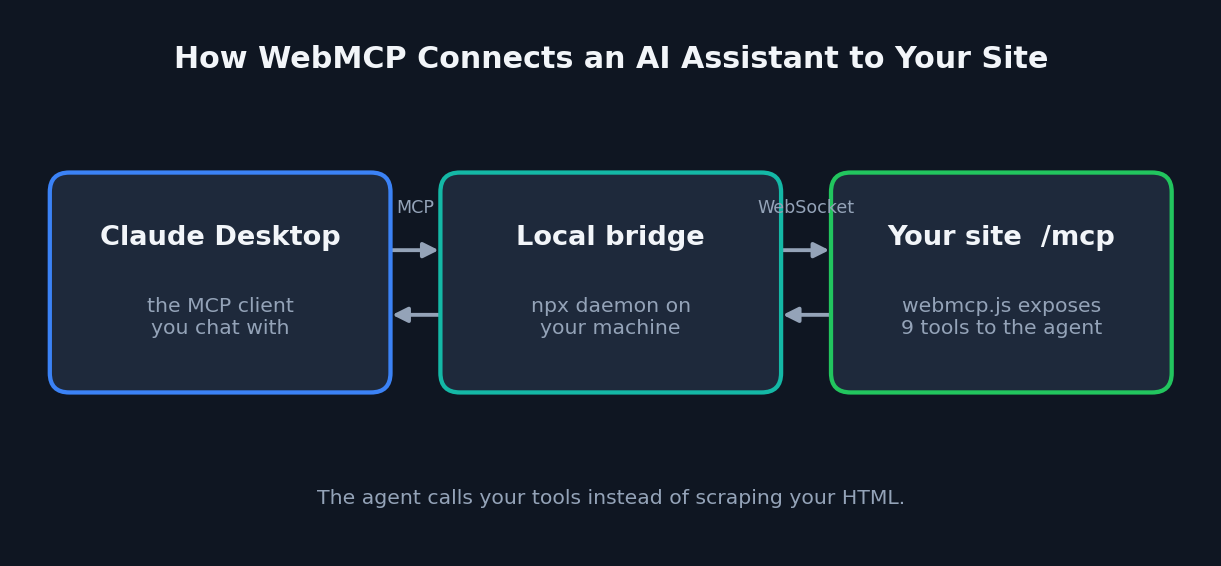
WebMCP lets an AI assistant like Claude connect directly to your WordPress site and answer questions about your services, your blog, and where to guest post, instead of scraping your pages like a search bot. It hands the assistant a set of tools, so the agent talks to your site rather than guessing at your HTML.
I added WebMCP to christopherjanb.com myself, on my real WordPress site, not a sandbox or a fresh test install. It took most of a day, it broke nine separate times, and I learned more from the breaking than from the parts that worked.
This is the honest build log, with the actual fixes, so you can decide whether it is worth your time and skip the potholes I stepped in. By the end you will know what to upload, where it goes, and which nine things will try to stop you.
What WebMCP Actually Is
Here is the part most explainers get wrong. There are two different things called WebMCP, and they are not the same.
The first is an open source library that works today. You drop a small script on your page, register some tools, and a visitor running an MCP client (like the Claude desktop app) can connect to your site through a local bridge. This is the version I used. The repo is github.com/jasonjmcghee/WebMCP, the project site is webmcp.dev, and I was on the 0.1.x release line.
The second is an emerging web standard being built into browsers. WebMCP was published as a W3C Draft Community Group Report on February 10, 2026, and shipped as an early preview in Chrome 146 Canary behind a flag. It is co-developed by Google’s Chrome team and Microsoft’s Edge team, with native support across Chrome and Edge expected in the second half of 2026, while Firefox and Safari are engaged in the spec process but have not committed to timelines. That version needs no bridge and no setup: any AI agent visiting your page just sees the tools. It is the future, but it is not shippable yet.
Why does this matter? Because if you read about WebMCP and expect agents to start using your site automatically, the library version will disappoint you. It is opt-in and a little fiddly for the visitor. The standard is what makes it effortless, and that is still months out. Knowing which one you are dealing with sets your expectations correctly before you spend an afternoon on it.
Why I Bothered
I work in SEO and content for a living, so I spend a lot of time watching how people find things, and that behavior is shifting fast. More people now ask an AI assistant to do the searching and summarizing for them, and when an assistant reads your site, it reads it like a scraper guessing at your structure.
WebMCP turns that guesswork into a clean conversation. Instead of an agent parsing my HTML and hoping it finds my services, it can call a tool that hands back exactly what I want it to know.
Am I getting a flood of agent traffic from this today? No, and I want to be straight about that. Almost nobody is going to install a bridge to talk to my site right now. I did it anyway for three reasons that have nothing to do with today’s traffic: it is a working demo I can show the exact SEO and SaaS clients I want, it is an early signal that compounds with the GEO work I already do, and it is hands-on practice for the day a client asks me to build it. Being early and having actually done it is worth more to me than passive traffic I do not have yet.
What I Built
My site is a portfolio and services site, not an app full of buttons, so my tools are mostly read access plus one action. I exposed nine of them:
| Tool | What it returns |
|---|---|
get_site_info |
Who I am, positioning, experience, and how to engage |
list_services |
The five services with one-line descriptions and URLs |
get_service |
Full detail on any single service page |
get_proof |
Client roster, publications, and testimonials |
list_posts |
The blog inventory, pulled from the sitemap |
search_posts |
Blog posts matching a keyword |
get_post |
The full text of any single post |
get_guest_post_opportunities |
My guest posting directory, optionally by niche |
book_call |
The booking link, framed to qualify the visitor |
The one insight I would tattoo on the wall: every tool description is conversion copy written for a language model, not a human. When I describe the booking tool, I am not writing UI text. I am telling the agent who the call is for and how it works, so that when someone asks an AI assistant “is this person a fit for my B2B SaaS site,” the assistant answers well and points them to my calendar. The tools are sales collateral aimed at a reader that happens to be an AI.
I tested this exact scenario afterward. I told the assistant my B2B blog traffic was sliding and asked if I was a fit. On its own it pulled my site info, my services, and my proof, recommended my content reoptimization service, and surfaced the booking link. That is the whole point working end to end.
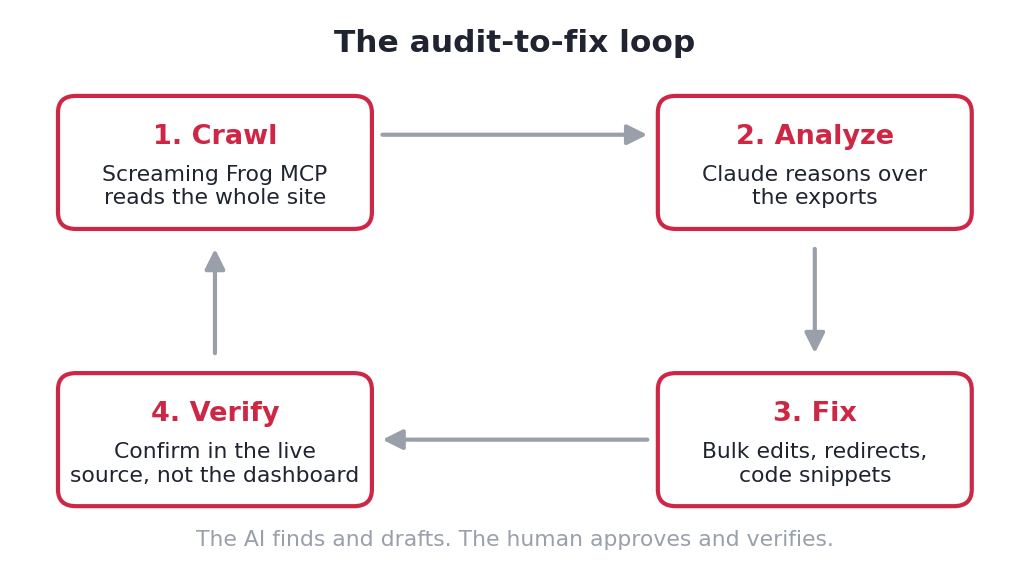
The Setup, Step by Step
Here is the actual sequence on WordPress. It is replicable if you want to follow it, and the setup steps map cleanly to HowTo schema if you mark it up.
- Get the script file. This tripped me up immediately, so save yourself the hunt: the file is not at the top of the GitHub repo. It lives inside the release download at
src/webmcp.js, and the readme points you to the releases page rather than the source tree. It is browser-ready as is, no build step for a normal modern site. - Upload that file to your site root so it loads at
yoursite.com/webmcp.js. Root means the same folder as wp-config.php, not inside wp-content. Visit the URL directly afterward. If you see JavaScript, you are good. If you see a 404, it is in the wrong folder. - Create a page with the slug
mcpand write visible copy explaining what the page is and how to connect. This is the page agents and curious humans land on. - Add your tool-registration script through WPCode as an HTML Snippet, set to load in the site-wide footer. The reason it has to be an HTML Snippet and not the post editor is coming up in a second.
- Set up your MCP client. For testing that means the Claude desktop app, a small config entry, and a connection token.
That is the clean version. Now here is what actually happened.
Everything That Broke
This is the part you cannot get from a generic tutorial, because a generic tutorial never ran into any of it.

1. WordPress Mangled My Script
I pasted the registration script into the page and it silently broke. WordPress has a feature called wpautop that wraps things in paragraph tags to tidy your writing, and it happily wrapped my script tags mid-function, turning working JavaScript into garbage. The fix was to stop using the post editor entirely and put the script into a WPCode HTML Snippet, which bypasses wpautop. Lesson: on WordPress, code does not belong in the content editor. It belongs in a snippet tool built to leave it alone.
2. The Page-Targeting Setting Quietly Failed
I wanted the widget to load only on my mcp page, so I used WPCode’s option to target that one URL. It did nothing; the matching logic checked the full URL in a way that never fired. Instead of fighting it, I set the snippet to load site-wide and put a one-line check at the top of my own script that runs only if the path ends in mcp. Lesson: when a plugin’s built-in targeting misbehaves, gate it yourself in code. You control that; the plugin’s UI you do not.
3. The Command Could Not Find npx
Once I moved to connecting the desktop client, the bridge would not start. The config told it to run npx, but the desktop app launches things with a stripped-down PATH, so a short command was not found even though it works fine in my terminal. The fix on Windows was to run it through the command-prompt wrapper instead of calling npx directly. Lesson: anything launched by a desktop app should assume a minimal environment and use full, explicit commands.
4. The Config I Edited Was Not the Config It Read
I edited my desktop config, saved it, restarted, and nothing changed. The app had moved to reading its config from a virtualized location after an update, while the edit button still opened the old file. I was editing a file the app no longer used. Lesson: after a desktop app update, do not assume the file you have always edited is the one being read. Confirm the path, or use the in-app editor that opens the live file.
5. Invalid Token, on Repeat
My daemon log started flooding with “invalid token.” The connection depends on both sides agreeing on a shared secret, and mine had drifted out of sync because the token regenerated while one side still held the old one. The fix was to read the real token straight out of the server’s env file and paste that exact value into the client config. Lesson: when two processes authenticate with a shared token, do not guess at it, read the source of truth and copy it verbatim.
6. A Dead Process I Thought Was Alive
Then came thousands of “connection refused” errors. The bridge kept trying to reach a server on a port where nothing was listening, because of a stale process-ID file: an old server had died, but its ID file was still on disk, so the bridge assumed a server was running. The fix was to kill every stray process, delete the stale state, and bring exactly one server up cleanly. Lesson: when something insists it is “already running” but nothing answers, hunt for stale lock or PID files first.
7. My Tools Were Invisible Because of One Missing Word
Everything connected, the client saw my server, but it reported zero tools. The tool definitions each carry a small schema describing their inputs, and mine were technically malformed. A no-input tool needs a schema that says “this is an object with no properties,” and I had given it a blank instead. My lenient local server registered them anyway; the desktop client validated strictly and silently dropped all nine. The fix was a proper, complete schema on every tool. Lesson: validate against the pickiest consumer, not the most forgiving one.
8. The Connection Kept Timing Out Mid-Test
The widget disconnects after about five minutes of sitting idle, for security. I did not know that, so every time I tabbed away to fiddle with the config, the channel quietly dropped, my tools deregistered, and I kept fixing problems that were not problems. The fix was to raise that timeout while testing and keep the tab in front of me. Lesson: when a system has an idle timeout, your slow, careful, switch-between-windows debugging style is the exact thing that breaks it.
9. Registered Is Not the Same as Available
Finally, even with everything connected, the assistant said it had no such tool. The connector showed up, but the tools were not loaded into the conversation, because the client treats “a connector exists” and “its tools are active in this chat” as two different states. The fix was getting the order right: bring the server up, connect the browser and register the tools first, then start the client, and test in a fresh chat. Lesson: connection and availability are separate, and the wrong order leaves you staring at a connector that does nothing.
How I Actually Figured This Out
The single most useful move in the whole process was not a fix. It was opening the log files.
For a long stretch I was guessing, changing one thing, restarting, and hoping. That is slow and it teaches you nothing. The moment I started reading the client’s connection log and the server’s console output side by side, the real cause showed itself almost immediately. The invalid-token flood, the connection-refused errors, the empty tool list, all of it was written plainly in the logs while I was busy theorizing.
If you take one thing from this, take that: when a multi-part system misbehaves, stop guessing and read what each part is actually saying. The answer is usually already on screen.
Is It Worth Doing Right Now?
Here is my honest call, because you deserve one before you spend an afternoon on this.
As a traffic channel today, no. The library version is opt-in and technical enough that real visitors will not use it. If you are hoping this brings agent traffic this quarter, it will not.
As a demo, a positioning signal, and practice, yes. I can now point a prospect at a live thing instead of a slide, it reinforces that I am tracking where search is going, and when a client asks me to build this, I have already bled on it once. For me, in my line of work, that is worth the day.
If being early on AI search does not yet matter to your buyers, wait for the native browser standard. It is coming, it needs no bridge, and it will make all of this effortless.
The Cheap Wins That Compound
Whether or not you build the full thing, two smaller moves cost almost nothing and pay off into the native standard later.
Add an llms.txt file to your site. It is a plain-text map of your key pages for AI systems to read, the way robots.txt is for crawlers. This folds directly into GEO work and is the highest-leverage thing on this list.
Get your contact or booking form ready to be agent-callable. When the native WebMCP standard lands, that is the action that actually earns money, so it is where I would point your effort first.
Where This Is Heading
The thread running through all of this is simple. The way people discover and use content is moving from “a human reads a page” to “an agent uses a site on a human’s behalf.” WebMCP is an early, rough, honest attempt at building for that world. It broke nine times on me and I would still do it again, because I would rather hit these walls now, on my own site, than the first time a client is watching.
If you want content and an SEO approach built for where search is actually going rather than where it was five years ago, that is the work I do. You can book a call with me and we can talk about your site.
Frequently Asked Questions
Is WebMCP the same as the standard coming to Chrome?
Not quite. There are two: an open-source library you can use today (what this post covers) and a native browser standard, published as a W3C draft in February 2026, with Chrome and Edge support expected in the second half of 2026. The library needs a local bridge; the standard will not.
Do I need to know how to code to add WebMCP to WordPress?
A little. You upload one script, create a page, and add a snippet through WPCode. You do not write the library, but you will edit a tool-registration script and a small client config, and you will be calmer about it if a command line does not scare you.
Will adding WebMCP bring me AI traffic right now?
No. The library version is opt-in and a visitor needs a local bridge to use it, so almost nobody will. Treat it as a demo, a positioning signal, and practice, not a traffic channel, until the native standard ships.
What is llms.txt and how does it fit?
It is a plain-text file that maps your key pages for AI systems, like robots.txt for crawlers. It is far easier than a full WebMCP build, it supports your GEO visibility now, and it carries forward when the native standard arrives.